Lakeflow
Solution
データ活用を止めないために、データパイプラインを本番運用できる形に整えます
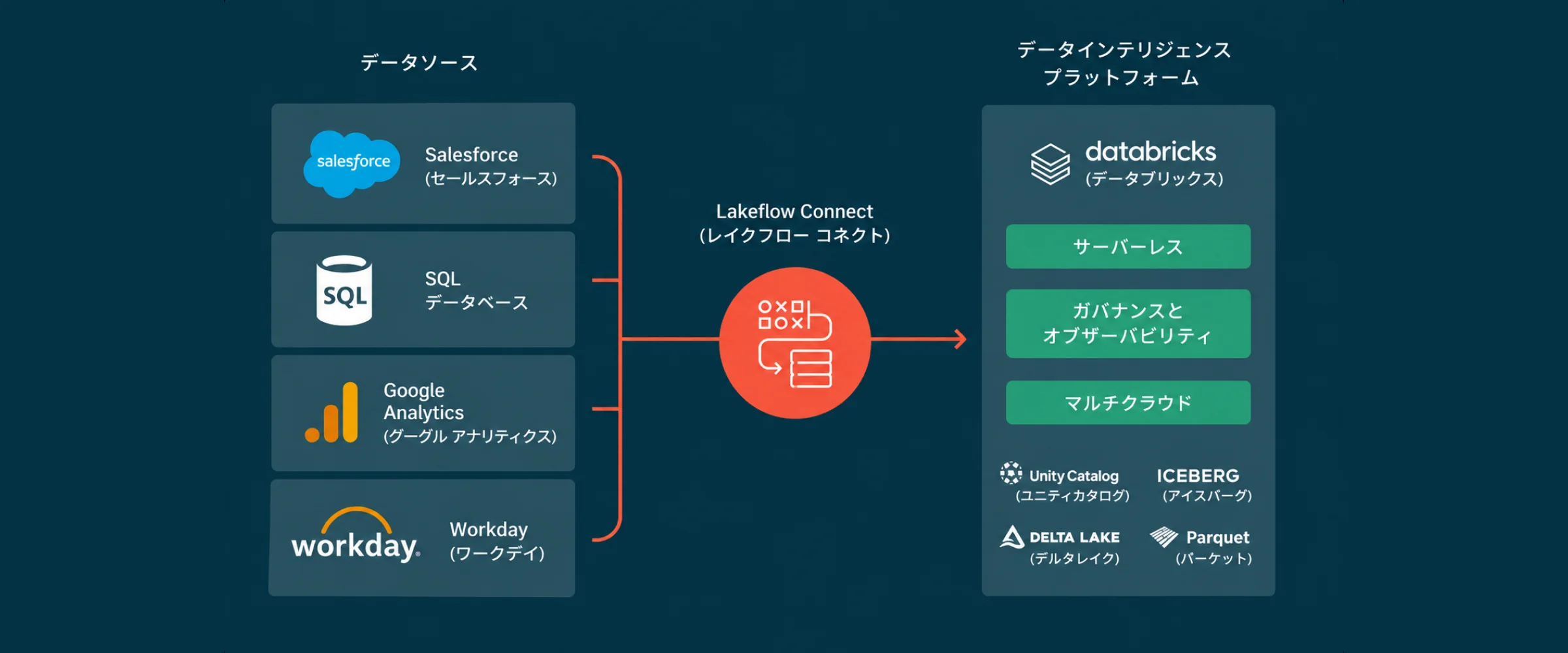
Lakeflow とは
Lakeflowとは、Databricks上でデータの取り込み・変換・オーケストレーションを統合的に扱うためのデータエンジニアリング機能です。 データ基盤では、データを集めるだけでなく、必要なタイミングで取り込み、加工し、利用部門や分析・AI活用に渡せる状態を継続的に保つことが重要です。しかし、処理がノートブックや個別スクリプトに分散したままでは、依存関係が分かりづらくなり、障害時の切り分けや運用引き継ぎが難しくなります。 Lakeflowを活用することで、Databricks上のデータ処理をパイプラインとして整理し、スケジュール実行、タスク間の依存関係管理、監視、通知、再実行などを運用しやすい形に整えられます。Lakeflow Connectではデータ取り込み、Lakeflow Declarative Pipelinesでは宣言型パイプライン、Lakeflow Jobsではワークフローのオーケストレーションを担う構成になっています。
お問い合わせ弊社では、Lakeflowを単なるETL機能としてではなく、データ基盤を本番化し、継続的に運用していくための設計テーマとして扱います。PoCで作った処理をそのまま本番化するのではなく、監視、障害時対応、権限、コスト、運用体制まで含めて、実運用に耐えられるデータパイプラインの構築を支援します。
こんな課題はありませんか?

データ処理がノートブックや個別スクリプトに分散しており、全体の流れを把握しづらい

PoCでは動いたものの、本番運用に向けた監視・再実行・障害対応の設計に不安がある

パイプライン障害時に、どこで失敗したのか、どのデータに影響があるのかを把握するのに時間がかかる

データ基盤を継続運用したいが、設計・構築・運用を社内だけで進めるのが難しい
Lakeflow がもたらす価値
 データ処理の流れを可視化し 運用しやすくします
データ処理の流れを可視化し 運用しやすくします
データの取り込み、変換、更新、後続処理への連携をパイプラインとして整理することで、処理の依存関係や実行順序を把握しやすくなります。属人的なノートブック運用や個別スクリプト管理から脱却し、引き継ぎや保守をしやすい状態を目指せます。
 統合のスピードと安定性を 両立しやすくします
統合のスピードと安定性を 両立しやすくします
複数のデータソースを扱う場合でも、取り込みから変換、提供までの流れを整理することで、拡張しやすいデータパイプラインを構築できます。新しいデータソースや分析要件が追加された場合も、全体の整合性を保ちながら改善しやすくなります。
 障害時の切り分けと 影響把握をしやすくします
障害時の切り分けと 影響把握をしやすくします
パイプラインの実行状況やタスク単位の結果を確認しやすくすることで、失敗箇所の特定や再実行の判断がしやすくなります。データ活用を止めないためには、障害が起きないことだけでなく、起きたときに素早く復旧できる設計が重要です。
Lakeflow の検討は、機能選定よりも、どこまで運用を見据えるかが重要です。 本番化を前提にした進め方を整理したい場合は、ご相談ください。
提供内容
既存のデータ処理フローの棚卸し
現在のデータ取り込み、変換、更新処理、利用部門への連携方法を確認し、 運用上の課題や属人化しているポイントを整理します。
データ取り込み・変換要件の整理
データソース、更新頻度、データ量、処理タイミング、品質要件、 後続の分析・AI活用要件を整理し、パイプライン設計の前提を明確にします。
Lakeflowを前提にしたパイプライン設計
Lakeflowを活用し、取り込みから変換、提供までの処理を 本番運用しやすい形に設計します。タスク間の依存関係や再実行方針も整理します。
Databricks環境への構築・実装支援
設計方針に基づき、Databricks環境上でパイプラインを構築します。 既存データやUnity Catalog、メダリオンアーキテクチャとの整合性も考慮します。
監視・障害対応・運用ルールの設計
実行状況の確認、失敗時の通知、再実行、影響範囲の確認、 運用担当者への引き継ぎなど、本番運用に必要なルールを整備します。
運用定着・引き継ぎ・内製化の支援
導入後も継続的に運用できるよう、ドキュメント整備、 管理者向け支援、社内運用への引き継ぎ、改善活動を支援します。